Utiliser un combo RAM/VRAM pour faire de l'IA

Tester un mix RAM et VRAM pour exécuter des LLM avec Ollama, limites réelles, latence GPU CPU et pourquoi cette approche low cost déçoit sans NPU.
Aujourd'hui, on va tenter une solution à moindre coût pour faire tourner des modèles larges sur Ollama sans avoir à débourser des mille et des cent.
Je vais effectuer plusieurs tests afin que vous n'ayez pas à le faire vous même... Oui, je me sacrifie pour la science !

Ma stratégie, au lieu d'acheter un GPU qui coûte > 2000€, je vais opter pour un GPU que j'ai déjà:
- Une RTX 4070 Ti 12 Go
- Un serveur Xeon 2680v4 14c/28t qui me permet de tenir énormément de RAM...
Je vais y mettre 4 barrettes de 32go soit 128go de RAM au total.

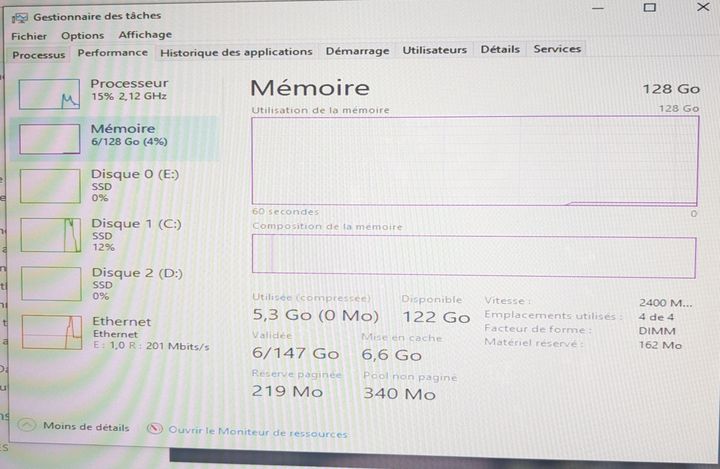
J'ai vu plusieurs fois des builds IA qui faisaient un mix RAM/VRAM. La plupart du temps, les CPU utilisés étaient du Apple Silicon M(x) ou des CPU récent qui contiennent une partie NPU (Neural Processing Unit).
Quid d'un CPU standard ?
Essayons d'abord des modèles très petits:
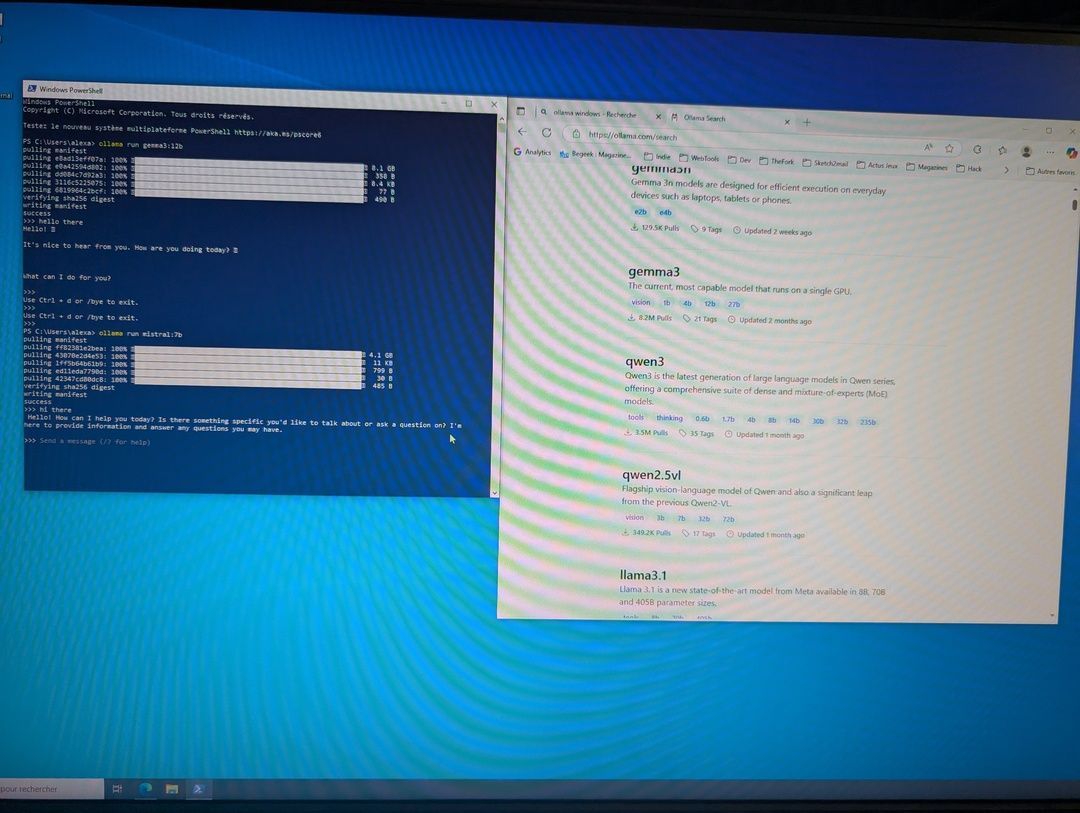
Je charge les modèles gemma3:12b et mistral:7b respectivement de 8go et 4go. Mais pour le moment c'est simple, je reste dans les 12go de VRAM disponible sur le GPU.
Comme le modèle est intégralement chargé sur le GPU, je n'ai quasiment aucune latence, tout fonctionne bien.
Passons maintenant à quelque chose de plus tendu.
Je commence par un qwen3:32b de 20go:
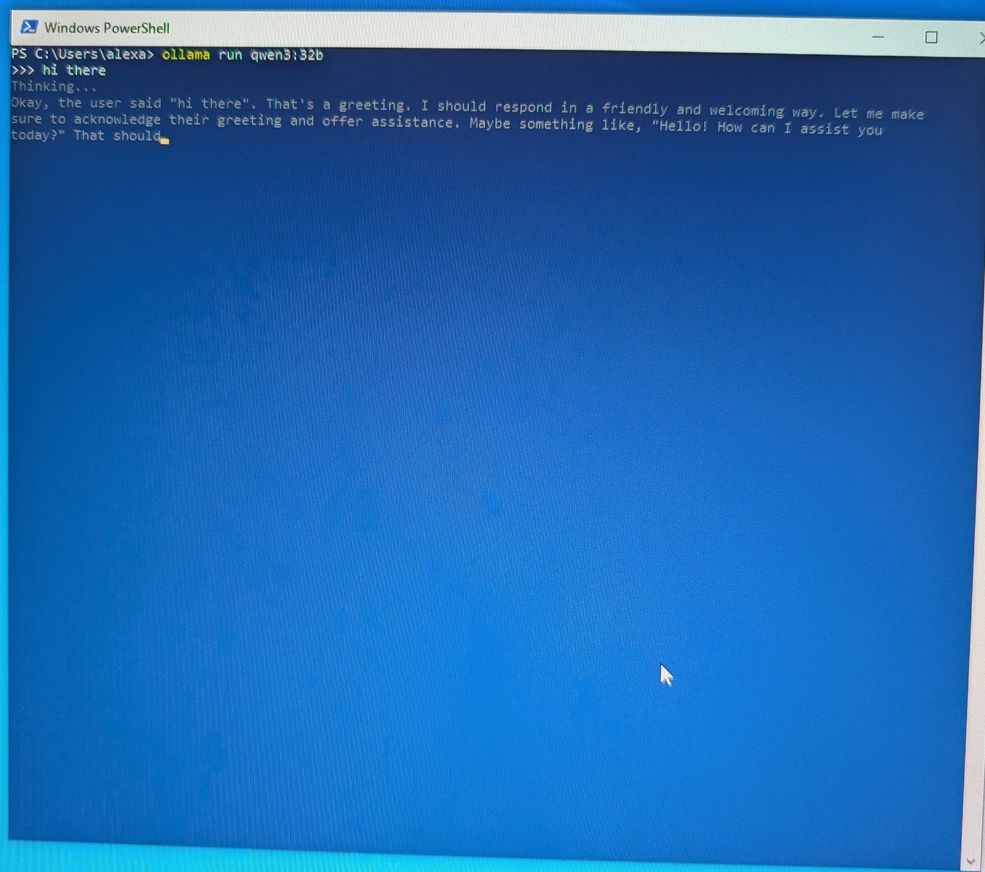
Honnêtement, je le vois immédiatement que le modèle cohabite entre VRAM et RAM , je dépasse de 8go la mémoire disponible, donc 2/3 de la tokenisation peut être traitée sur le GPU seul, mais on sent qu'il y a de la lenteur...
Essayons maintenant quelque chose de bien plus lourd:
Je charge un deepseek-r1:70b de 42go:
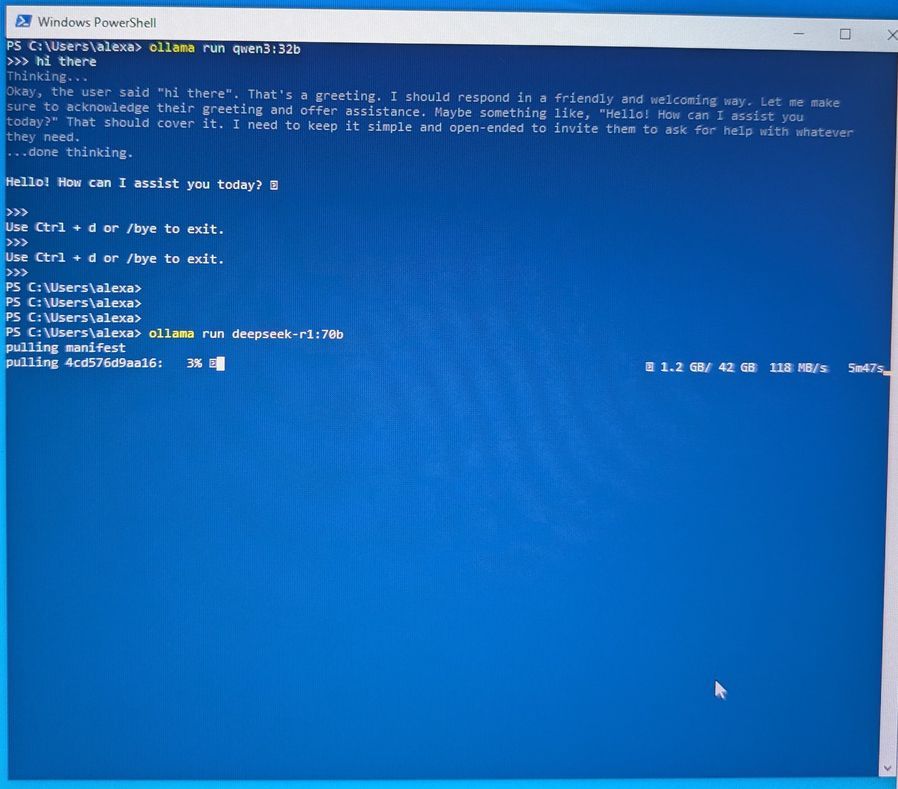
Là, c'est littérallement l'enfer !
Sur les 42go du modèle, je fais tenir 12go sur la VRAM du GPU et 30go sur la RAM. On le sent immédiatement ! La moindre requête simple comme bonjour, met plus d'une minute à réfléchir et la vitesse de réponse est archi lente.
Conclusion
Cette approche low-cost pour utiliser des LLMs n'est pas très intéressante et lorsque vous voyez que des gens le font sur un Mac mini , un Mac pro etc où sur des PC récent avec énormément de RAM , gardez en tête que l'architecture CPU n'est pas la même.
Les processeurs Apple M1 , M2 , M3 , etc. embarquent un NPU (Neural Processing Unit), un petit circuit dédié aux calculs IA. Contrairement à un CPU classique, le NPU est optimisé pour traiter efficacement des modèles neuronaux en parallèle, avec une consommation très faible.
Résultat : ils peuvent inférer un LLM léger directement en RAM , sans passer par un GPU , ce qui évite les aller-retours coûteux entre la RAM et la VRAM. C’est aussi ce qu’on retrouve dans les dernières générations de processeurs Intel (Core Ultra) et AMD (Ryzen AI), avec leurs propres unités IA intégrées.
Donc avec ces composants, vous pouvez utiliser votre RAM pour loader un modèle et utiliser le CPU pour inférer. Dans mon cas avec un Xeon de 2014, n'ayant pas de NPU je ne peux pas le faire et c'est à cause de cela que j'ai autant de lenteurs...
Pour résumer, à moins d'avoir un ordinateur très récent, je ne conseille pas de faire un mix RAM /VRAM car dans mon cas, l'inférence se fait toujours sur le GPU et le fait d'avoir une partie du modèle en RAM force une latence pour faire les allers-retours RAM et GPU.

Alexandre P.
Développeur passionné depuis plus de 20 ans, j'ai une appétence particulière pour les défis techniques et changer de technologie ne me fait pas froid aux yeux.
Poursuivre la lecture dans la rubrique Projets

