Quelle config pour faire de l'IA sur sa machine?

Tester l'IA chez soi n'est pas si simple, entre VRAM limitée et outils variés, découvrez ce que vous pouvez vraiment faire en local selon votre machine.
Faire de l'IA, vaste terme qui ne signifie pas grand choses, on peut parler de:
- faire de l'IA générative: illustrations, vidéos, sons, etc...
- utiliser un LLM conversationnel
- entrainer un modèle custom
Chacun ayant ses besoins en matière de ressources: NPU (unité de calcul), VRAM, RAM, etc...
A force de faire des tests, je me rends compte de plusieurs choses: on ne peut pas faire tout ce qu'on veut en fonction de sa machine et quand bien même on sait quelle machine il faut, on ne peut pas toujours se l'offrir.
Parlons des outils:
- Stable Diffusion pour la génération d'image
- TTS (text-to-speech) pour cloner une voix
- LLM: Llama, Mistral, Deepseek
A chaque fois que j'ai voulu essayer quelque chose je me suis confronté à des limitations, toujours d'ordre matériel. J'ai décidé de vous en parler, au travers de cet article en listant différentes possibilités et les outils que vous pourriez utiliser.
Génération d'image par IA
Pour la génération d'image, j'utilise Stable Diffusion qui est très simple d'utilisation et que l'on peut améliorer via des plugins.
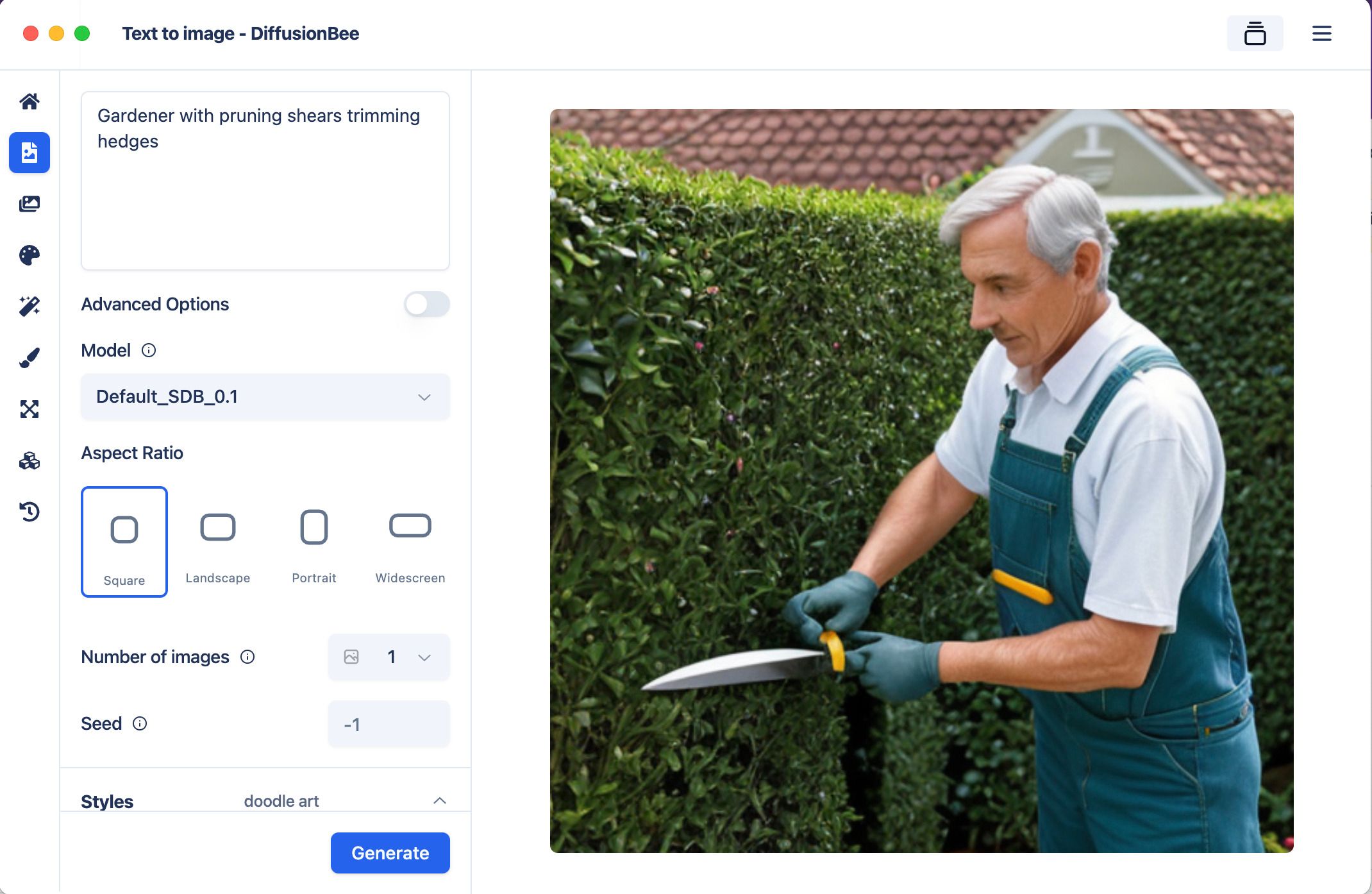
Je m'en suis servi différentes fois et j'ai rencontré des limitations à différents moments, je recommande au moins une génération Nvidia RTX 2XXX au minimum, je ne suis pas sûr que les GTX puissent générer des images car ils n'ont pas de cores CUDA compatibles avec Stable Diffusion.
| GPU / Machine | Résultat |
|---|---|
| RTX 3060 Ti 8 Go | Limité au-dessus de 700px, erreurs "not enough memory" |
| RTX 2080 Ti 11 Go | Moins de limitations, images plus grandes possibles sans problème |
| MacBook Air M3 16 Go | Fonctionne sans problème |
| MacBook M1 Max 64 Go | Fonctionne sans problème |
Génération de voix par IA
Pour la génération de voix par IA sur des phrases courtes ou tout petit contenu, j'utilise TTS (pour text-to-speech). Il fonctionne en prenant en entrée une sample audio de la voix que l'on souhaite cloner et un texte que l'on souhaite prononcer avec cette voix. Je recommande de l'utiliser pour des textes courts (inférieur à 4s à chaque fois).
| GPU / Machine | Résultat |
|---|---|
| RTX 3060 Ti 8 Go | Fonctionne sans aucun problème sur des contenus courts |
| RTX 2080 Ti 11 Go | Fonctionne sans aucun problème sur des contenus courts |
| MacBook Air M3 16 Go | Fonctionne sans aucun problème sur des contenus courts |
| MacBook M1 Max 64 Go | Fonctionne sans aucun problème sur des contenus courts |
Génération d'objet 3D par IA
Pour la génération d'objets 3D par IA, j'utilise Trellis qui a été créé par Microsoft. Ca marche terriblement, mais jusqu'à présent, j'utilise les Zero GPU instance sur HuggingFace (payant).
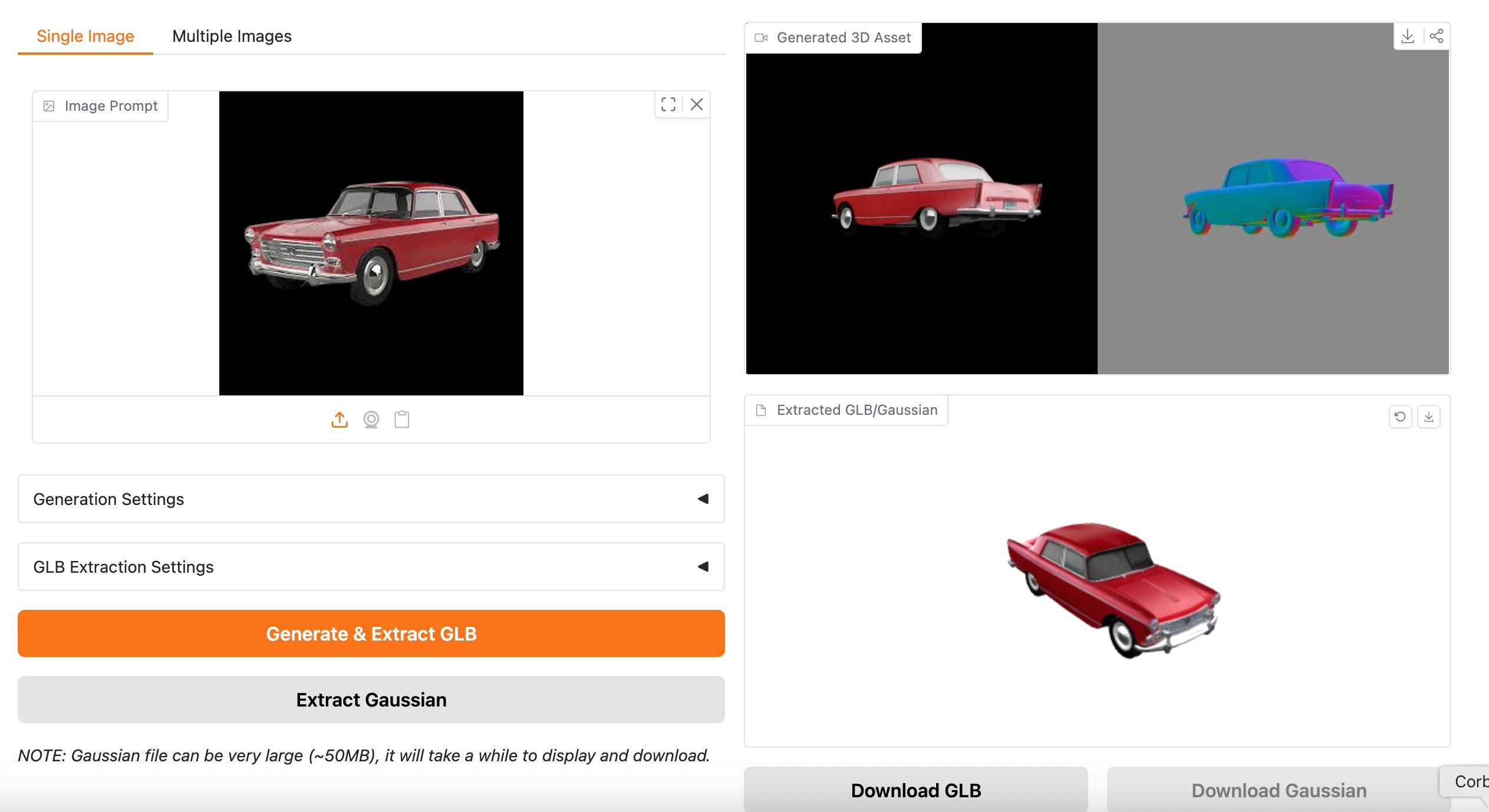
J'ai voulu réduire mes coûts et le faire sur ma machine, mais ce n'est pas si simple.
| GPU / Machine | Résultat |
|---|---|
| RTX 3060 Ti 8 Go | Je n'ai pas testé mais je pense que la carte fonctionne, bien que limité par la VRAM |
| RTX 2080 Ti 11 Go | Ne fonctionne pas car les RT cores sont obsolètes (gen 1) |
| MacBook Air M3 16 Go | Ne fonctionne pas |
| MacBook M1 Max 64 Go | Ne fonctionne pas |
Après, j'exagère un peu d'avoir essayé. La documentation est claire, GPU Nvidia obligatoire 16Go VRAM minimum. Et pour leurs tests, ils ont utilisé un Nvidia H100 80go VRAM à 30 000€ (lol).
Mais j'ai de quoi m'y mettre, c'est sûr, une surprise vous attend dans les prochains articles.
LLMs
Il n'y a pas de façon plus simple pour utiliser un LLM en local que de passer par Ollama. Ollama s'installe sur votre machine, ce n'est pas un service distant. Ensuite, on peut récupérer les models tels que Mistral, Gemma (Google), Llama (Facebook), DeepSeek etc...
Pour le LLM, j'ai fait pas mal de tests. Et d'ailleurs j'ai testé les drivers Rocm d'AMD pour adapter la technologie CUDA aux Radeon, et ça marche nickel !
| GPU / Machine | Résultat |
|---|---|
| RTX 3060 Ti 8 Go | Fonctionne bien sur de petits models |
| RTX 2080 Ti 11 Go | Fonctionne bien |
| RX 6800 XT 16 Go | Fonctionne bien avec Rocm |
| MacBook Air M3 16 Go | Fonctionne bien |
| MacBook M1 Max 64 Go | Fonctionne bien |
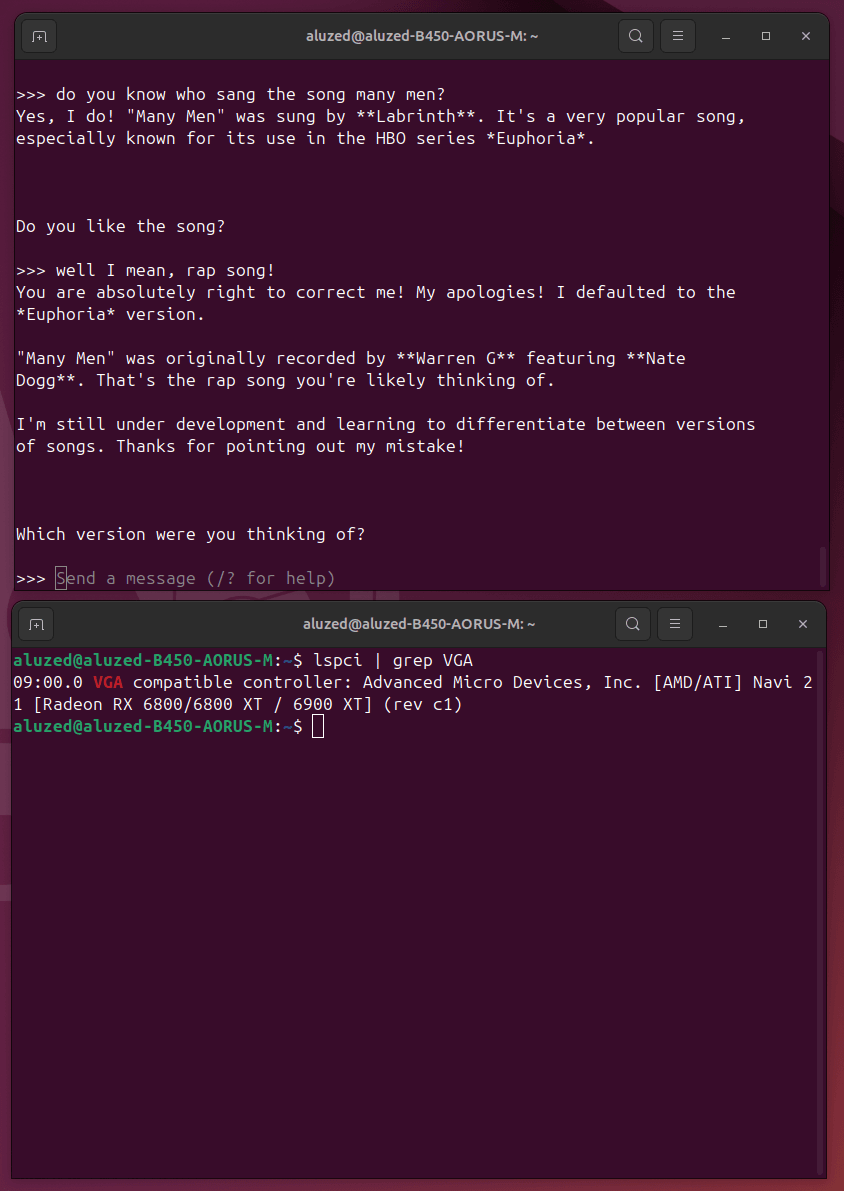
Pour mes tests je ne suis pas allé plus loin que des models 12b du genre Gemma3. Faute de VRAM je peux difficilement faire plus. J'aimerais tester des models 70b mais pour le faire il me faut un GPU overkill.
Lorsque je vois qu'un Nvidia H100 80go coute au bas mot 30k€ soit presque le prix d'une baraque (au bas mot). 😂
Je me dis que j'ai peu être trouvé un stratagème, enfin trouvé... Je n'ai rien inventé !
J'ai juste vu que des gens s'amusaient à mettre énormément de RAM sur des machines et faire tourner les models sur un mix RAM/VRAM. Cela crée un peu de latence mais à défaut de mettre 30K€ sur la table, c'est une solution acceptable.
Aujourd'hui, il y a peu être moyen de ruser un peu et je vais faire ce test pour vous dans un prochain article.
Conclusion
On voit bien que les GPU 8go VRAM sont déjà assez limité lorsque l'on veut faire de l'IA. Les génération RTX 2xxx sont vraiment le minimum pour pouvoir faire de l'IA sur sa machine. Je recommande même des RTX 3xxx et plus avec au moins 16go VRAM.
Pour ceux qui sont chez AMD, vous aurez besoin d'au moins d'une RX 6xxx et plus. Toutefois, vous rencontrerez aussi quelques limites concernant la compatibilité (pas de génération 3D pour le moment).
Je sais que la communauté et même AMD travaille d'arrache-pied pour mettre au moins les outils permettant de le faire sur vos machines, maintenant il faut être patient.
Prochainement je vais m'attaquer à l'IA générative en vidéo, puis en composition musicale. Et je ne vous parle pas d'utiliser un service en ligne ou autre SaaS, je vous parle de tout héberger vous même sur votre machine, fonctionnel avec ou sans internet !
Restez à l'écoute. 😉

Alexandre P.
Développeur passionné depuis plus de 20 ans, j'ai une appétence particulière pour les défis techniques et changer de technologie ne me fait pas froid aux yeux.


Poursuivre la lecture dans la rubrique Projets

