
Comment écrire ses migrations de base de données PostgreSQL
Lorsque l'on travaille sur un projet qui communique avec une base de données SQL, on utilise souvent des fichiers de migrations afin que chaque développeur puisse se tenir à jour des changements de structure sur la base de données. Cependant il convient de les écrire efficacement.
Dans mes missions, j'ai rencontré beaucoup de projets où la structure n'allait pas et où il fallait repasser dessus pour éviter les problèmes de déploiement.
Les migrations SQL sont des fichiers qu'il faut écrire avec précaution car votre base de données est la ressource la plus importante de votre projet.
Le code se remplace, les langages sont interchangeables, que vous passiez par du PHP, du Node, du Rust ou du Python ne change absolument rien, en revanche, récupérer vos données en base est le socle sur lequel tout le reste vient s'appuyer.
Les directions de migration SQL
Certaines librairies tel que Knex.js (qui est un query builder) vous suggère de créer vos migrations toujours dans deux directions: Up et Down.
- Up étant la direction qui sert à appliquer votre migration
- Down étant la direction qui sert à annuler votre migration
C'est une organisation importante qui sert à revenir en arrière à tout moment.
Quel est le risque lorsqu'une migration SQL est mal écrite ?
Lorsque vous écrivez des migrations et Up/Down et que ces requêtes sont mal écrites (souvent en Down), vous aurez un problème lorsque vous allez rejouer le Up.
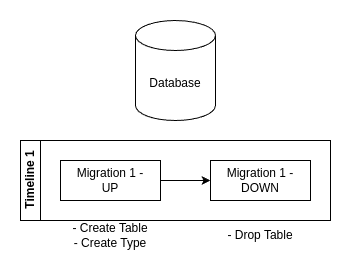
Dans cet exemple, 2 ressources sont créés à la migration Up, mais une seule est détruite lors de la Down.
Au prochain run, voici le résultat:
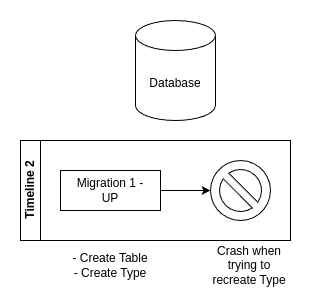
Le type n'ayant pas été détruit, il déclenche systématiquement une erreur au retry de la migration Up.
Comment régler ce problème de migration
- Toutes les ressources doivent être détruite lors de la migration Down.
- On peut essayer d'utiliser des transactions pour grouper les opérations, car il y a un second risque:
Lorsque vous effectuez une série de requête dans une migration Up, si l'une d'entre elle déclenche une erreur, les opérations d'au dessus sont tout de même appliqués.
Je vous recommande, d'utiliser une stratégie de Transaction/Rollback pour éviter d'écrire partiellement les opérations.
Le fait de tout grouper dans une Transaction, la migration se comportera comme un : "tout ou rien".
On peut même faire l'équivalent d'un bloc Try/Catch en Postgresql:
DO $$
DECLARE
-- Déclarer les variables nécessaires ici
amount_to_update NUMERIC := 100;
BEGIN
-- Commencer la transaction
BEGIN
-- Effectuer des opérations SQL ici
UPDATE account SET balance = balance - amount_to_update WHERE account_id = 123;
UPDATE account SET balance = balance + amount_to_update WHERE account_id = 456;
-- Si une erreur se produit, déclencher une exception
EXCEPTION WHEN others THEN
-- Afficher un message d'erreur
RAISE NOTICE 'Erreur lors de la mise à jour du compte : %', SQLERRM;
-- Rollback de la transaction
ROLLBACK;
-- Quitter la transaction
RETURN;
END;
-- Si tout s'est bien passé, committer la transaction
COMMIT;
END $$;
Quels sont les points à surveiller lorsque nous écrivons une migration SQL
Lorsque nous écrivons une requête SQL, nous devons veiller à l'idempotency.
L'idempotency ou encore en français l'idempotence, c'est le fait de pouvoir effectuer la même opération plusieurs fois avec toujours le même output. Le résultat obtenu ne change pas en fonction du nombre d'appels. Il n'a aucun effet de bord et aucun bug venant de la requête en elle même.
De même, nous devons veiller à ce que les requêtes down, déconstruisent bien les requêtes up, car un oubli peut causer plusieurs problèmes par la suite.
L'idempotency pour les requêtes SQL
C'est un principe important lorsque vous écrivez vos requêtes, cela signifie que vous pouvez appeler 10 fois votre migration et que le résultat obtenu sera toujours le même.
Pour les requêtes de migration, l'idempotency est très simple à mettre en place.
CREATE TABLE IF NOT EXISTS ...
DROP TABLE IF EXISTS ...
De cette manière, la création ou le drop ne se fera toujours qu'une fois, et si la ressource n'existe pas, cette requête est tout simplement ignorée.
Cela marche pour bien plus de chose que la création et suppression de table.
Vous devez respectez au maximum les principes d'idempotence pour absolument toutes les ressources de votre base de données.
Je sais que certains seront sceptiques en se disant, "oui mais je ne peux pas utiliser IF NOT EXISTS pour les types par exemple...". Alors comme cela, non ! Mais il y a une façon de le faire:
DO $$
BEGIN
IF NOT EXISTS (SELECT 1 FROM pg_type WHERE typname = 'my_type') THEN
CREATE TYPE my_type AS
(
--my fields here...
);
END IF;
END$$;
Avec une transaction, on peut procéder à des vérifications avant la création du type.
Dans cette situation, s'ils existent, ils ne seront pas recréés. On évitera ainsi de rencontrer des problèmes de conflits.
Les migrations modernes
Aujourd'hui, des ORM (Object-Relational Mapping) un peu plus modernes comme Prisma font le travail de vérification des ressources existantes à votre place.
Je ne dirai pas qu'ils font absolument tout, mais cet outil vous évitera de créer pas mal d'erreur en faisant à la main la création des ressources.
L'aspect un peu plus négatif à mon goût mais qui plaira surement à une catégorie de personnes, c'est que cela passe par une syntaxe custom créé pour l'occasion qui se rapproche plus du développement que de la syntaxe de base de données.
Ce qui signifie à terme, perdre un peu de skill SQL pour en faire du code.
Cela est à mettre sur la balance, je ne me ferme pas d'une technologie ou de l'autre, j'utilise les deux dans mes projets, mais je préfère être clair sur ce point.
Les développeurs qui utilisent Prisma ne sont pas aussi skillés en DB que les développeurs qui écrivent à la main leurs requêtes, à juste titre.
Si on laisse faire l'abstraction, on perd notre familiarité avec les requêtes SQL et on a tendance à oublier les optimisations, comprendre comment sont faits les choses.
J'ai envie de transposer cela à mon expérience de la programmation. Pour vous donner une idée, en 2008 mon projet de Bac+2 était de coder en C++ un logiciel de gestion de panne distantes sur véhicule Peugeot 607 via un boîtier Canbus en USB. Cela implique une programmation de Socket, la gestion des DLLs et des libs, l'interception des erreurs et enfin lecture de trame et conversion analogique/numérique.
De même en 2012, quand je commençais à travailler, mon langage préféré pour le dev est le C#.
J'ai abandonné toutes ces technologies pour le Web, constatant qu'en entreprise, rares étaient les sociétés à investir dans des applications lourdes (nécessitant souvent des licences Windows payantes elles aussi) et moins de candidats.
Aujourd'hui, bien je pense être capable d'en refaire si l'envie me prend, je sais que j'ai beaucoup perdu de ces skills systèmes en utilisant de plus en plus de langages abstraits et haut niveau tels que Typescript.
La différence, c'est qu'aujourd'hui, on ne se passe toujours pas de base de données dans les projets.

Alexandre P.
Développeur passionné depuis plus de 20 ans, j'ai une appétence particulière pour les défis techniques et changer de technologie ne me fait pas froid aux yeux.

