
Pourquoi remplacer Meteor.js ?
Non ce n'est pas une blague pour un 1er Avril ! J'aime beaucoup le framework Meteor, d'ailleurs je vous en ai déjà parlé dans cet article. Tout d'abord, prenons le temps d'analyser la situation et tâchons de comprendre pourquoi nous pourrions remplacer Meteor.js par une autre technologie.
Les guidelines de Meteor.js, un parti pris très fort
Meteor.js vous force à structurer votre code autour de son architecture, c'est à dire qu'il vous faut exploiter les mécaniques de Tracker de manière à optimiser au mieux le render. Pour ma part, j'utilise toujours Meteor avec React, bien que j'ai commencé comme beaucoup de gens avec Blaze. Mais dès que la version React a été publiée, je ne suis plus jamais reparti en arrière.
Si vous n'êtes pas familier avec Meteor, les Trackers sont comme une sorte de hook qui va être déclenché lorsqu'un Model sera altéré côté base. En gros, s'il y a un update, c'est ce même tracker qui va prévenir votre composant pour que vous puissiez rafraîchir la donnée. On pourrait presque dire, qu'il s'agit tout bonnement d'un socket listener en attente d'un événement qui sera propagé au moment d'une écriture.
Meteor.js, les releases qui se font attendre
Très souvent sur Meteor, les nouvelles versions ont tendance à se faire attendre. Probablement que l'équipe qui maintient le projet a aussi du travail en parallèle et je comprends parfaitement que ce ne soit pas une priorité. Après tout, la version actuelle est toujours stable, tout fonctionne, il ne s'agit finalement que de quelques concepts en plus, ou rarement quelques dépréciations.
En ce moment même, la version 3 de Meteor se fait attendre, bien qu'ils aient mis en ligne une version 3 beta. Il faut savoir que la version définitive était planifiée pour Q4 2023, or vous voyez on est déjà en plein Q2 2024 et ce n'est toujours pas terminé.
J'apprécie beaucoup ce que fait la communauté Meteor et tout ce qu'ils ont apporté comme vision, comme intelligence. Le concept se veut simple: on s'occupe de propager l'information, écoute le bon événement et ton application sera réactive (pour tout ceux qui recherche le temps réel dans ce qu'ils produisent).
Pourquoi aurait-on besoin de la v3 de Meteor ?
Meteor dans sa version 2 s'appuie sur Fibers qui est déprécié depuis Node 16. Fibers servait à gérer l'asynchrone sur les anciennes versions de Node. C'était un outil qui permettait de wrapper du code asynchrone et de l'exécuter avec le côté "bloquant".
var Fiber = require('fibers');
function sleep(ms) {
var fiber = Fiber.current;
setTimeout(function() {
fiber.run();
}, ms);
Fiber.yield();
}
Fiber(function() {
console.log('wait... ' + new Date);
sleep(1000);
console.log('ok... ' + new Date);
}).run();
Depuis que Fibers a été déprécié, cela va probablement impacter Meteor en proposant une approche async/await, donc il va falloir se préparer à faire de la ré-écriture. Mais ce chantier ne pourra pas commencer tant que la version 3 ne sera pas définitivement sortie.
Si on devait refaire Meteor
Je me suis lancé dans une analyse par l'exemple, en me disant, si tu devais tout refaire, sans le framework Meteor, quels serait ta checklist en matière de feature ?
Premièrement, je ne souhaiterais pas forcément tout reprendre de Meteor. Il y a de bonnes idées, mais je pense que beaucoup de choses seraient surtout long à réimplémenter. De même, je mettrai sur la balance, ce que la feature m'apporte réellement avant de me lancer sur certains sujets.
- Un monorepo front et back : que je ne referai pas car dans une approche similaire, Next.js fait parfaitement le boulot.
- Un wrapper Mongo qui permet, côté front, de faire des appels socket et côté back les appels database avec une propagation après écriture : que je compte reproduire (plus simplement)
- Le wrapper Mongo côté front qui permet d'héberger une base allégée sur navigateur et permet de faire tourner votre application en dégradé : que je referai pas faute de temps, mais probablement dans une prochaine version.
Notre objectif
Avant d'aller plus loin, il convient de se fixer un objectif atteignable, même si l'on peut le redéfinir une fois atteint. Le but est de savoir où nous allons.
Faire une boîte à idées !
On doit pouvoir:
- Créer des comptes utilisateurs (s'enregistrer, se connecter, se déconnecter)
- Créer des sujets publics ou dans des groupes
- Poster ses idées dans les sujets
- Créer des groupes (publics ou privés)
- Interagir avec les groupes (demander à rejoindre, inviter, accepter un utilisateur, refuser, bannir, etc...)
- Manager les ressources (créer, supprimer)
- Toute l'application doit être temps réel
Nous sommes 5 jours après le début de la rédaction de cet article et toutes ces features fonctionnent et m'ont demandé quelques soirées et 7000 lignes de code.
Les outils pour recoder Meteor from scratch
Nous allons utiliser, pour le back:
- Node.js + Typescript
- ExpressJS, SocketIO, Multer, Moongoose > MongoDB et JsonWebToken
Nous allons rester sur une API très classique, mais qui a fait ses preuves en terme de robustesse.
Côté front, nous utiliserons:
- React.js + Typescript
- React-router-dom v6, React-Hook-Form, React-Query, Socket.io et Tailwind pour le CSS
Homemade Reactive project
J'ai passé quelques jours à coder ce projet pendant mon temps libre et avant d'aller dans le détail, voici à quoi ça ressemble lorsqu'on l'utilise.
Comment je m'y suis pris pour reproduire l'effet temps réel
Mon code n'est pas open source pour toute la partie logique car j'utilise des procédés que j'emploie dans les projets que je livre, mais je tacherai de vous expliquer dans les grandes lignes comment peut-on mettre en place cette mécanique d'auto refresh.
Premièrement, je n'ai rien changé à une API REST habituelle. J'appelle mes routes qui utilisent Mongoose et qui font les opérations d'écriture en base. Cependant, je me suis organisé pour que chacune des routes de type écriture, c'est à dire POST, PUT, PATCH, DELETE propagent une fois les opérations terminés, un message sur socket contenant la liste des models qui viennent d'être mis à jour.
Côté front, j'ai créé un Provider avec React pour instancier ma socket, et j'écoute un event, qui, une fois reçu, me permettra d'invalider des patterns de clé dans le cache de React-Query (via predicate). Ce qui signifie, que si j'ai un composant qui a une queryKey sur ['Users', 'id user'], dès que vois passer des modifications côté base, je vais propager un event pour rafraîchir les composants qui font des requêtes sur une ressource 'Users'.
De cette manière, le client sait quand est-ce que la ressource qu'il consulte est obsolète et gère lui même son re-render.
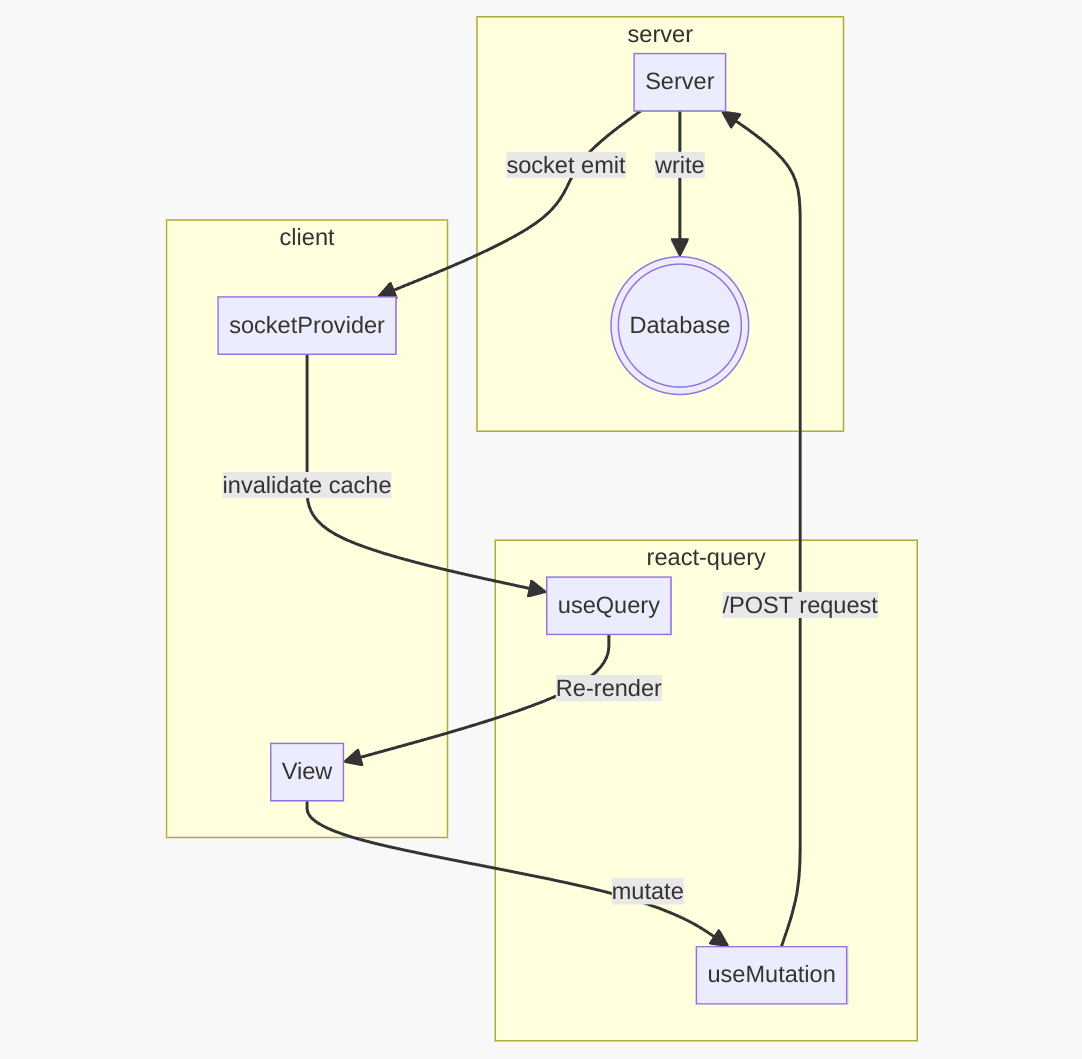
En 2024, il est simple de refaire un Meteor.js allégé
Il m'aura fallu une heure ou deux pour réaliser ce prototype de communication front/back (hors logique applicative), tant il est simple à déployer avec les outils d'aujourd'hui : React qui permet le re-render automatique dès qu'il y a mutation du state, React-Query qui gère un query cache, le pattern Provider/Context qui vient wrapper tous mes composants.
Désormais, nous avons clairement tous les outils pour recréer, à notre façon, un framework comme Meteor sans avoir la contrainte d'organisation repo, d'utiliser Tracker, de Meteor.call ou autre.
En contre-partie, sur cette implémentation simpliste, je n'ai pas de base dégradée. Mais je me suis penché sur le sujet, et je pense qu'il y a matière à gérer cela avec un PouchDB.
En revanche, j'aimerais, qu'en mode dégradé les bases locales ne contiennent que les changements en attente de synchronisation. C'est à dire que nous perdrons le côté historique des données, dès que la connexion serveur est interrompue. Mais cela permet de voir l'application front comme un système de transition, qui chercherait à vider les tables côté front pour confirmer l'insertion côté back.
Probablement pour une v2 😊

