Mon premier "gros" projet IA

Je vous parlais dernièrement de mon convertisseur de relevés bancaires pour le traitement comptable et les rapprochements. Celui-ci fonctionnait à l'aide d'exports bancaires CSV ou Excel. Qu'en est-il d'un relevé scanné fourni au format PDF ?
La GED
La GED (pour Gestion Electronique des Documents) est un domaine spécifique en informatique. Il s'agit de l'archivage et parfois de la compréhension de documents imprimés ou écrits. Pour ces derniers, on parle d'OCR (optical character recognition), comprenez la reconnaissance des caractères. Chaque domaine spécifique en informatique demande une compétence spécifique, c'est à dire que les professionnels experts de la GED sont souvent bien meilleurs que les autres sur le sujet, car ils ont eu le temps d'expérimenter beaucoup d'approches et ont une expérience dédiée au sujet.
Moi, qui suis un néophyte en la matière, je vous propose de faire un retour d'expérience sur le sujet car j'ai eu l'occasion de me pencher sur le traitement des relevés bancaires fournis en PDF scanné.
Le PDF
Le format PDF (portable document format) a été créé par Adobe, l'éditeur logiciel qui a créé entre-autres, Photoshop, le meilleur logiciel de retouche photo, à mon avis. Le PDF est un format permettant de récupérer un ensemble de pages dans un seul fichier. Jusqu'alors, scanner un document signifiait avoir l'extraction de chaque page en un fichier image différent.
Le PDF permet non seulement de regrouper plusieurs documents en un seul, et peut être généré au format texte ou au format image. Inutile de vous préciser que lorsque vous scannez un document en PDF, très souvent vous obtiendrez un format image, (même si certains scanner font l'effort de faire de l'OCR). Et c'est sur ce format spécifique, constitué d'images que nous allons nous pencher, car, il est beaucoup plus difficile à traiter.
Tesseract
Lorsque l'on veut faire de l'OCR, on utilise des librairies très connus tel que Tesseract. Cette librairie a été dévelopée par HP avec le soutien de Google et est distribuée sous licence Apache. Avec Tesseract, en quelques lignes dans un terminal on peut lui faire sortir un fichier texte depuis une source image.
Et cela peut se faire en une ligne très simple :
tesseract image.png output.txt
Alors, vous l'aurez compris, si la condition est d'avoir en entrée un fichier image, il suffit de splitter le PDF en plusieurs fichier image et de les passer chacune à Tesseract et le tour est joué ?
Et bien, ce n'est pas si simple !
Lorsque le fichier image est complexe (c'est notamment le cas d'un tableau de relevé bancaire avec des alignements dans toutes les colonnes et des données pouvant être d'un côté et de l'autre du document) Tesseract est incapable de gérer les alignements. Il n'est par rare qu'il mette tous les caractères à côté alors que dans le fichier source ils sont à 10 cm l'un de l'autre. De même, il n'est pas rare que Tesseract zappe littéralement des portions du fichier, que vous ne retrouverez pas en sortie !
Pourquoi faire du machine learning ?
Je vais vous expliquer maintenant pourquoi, j'ai opté pour une approche IA plutôt qu'un simple script étape par étape qui va passer les éléments à Tesseract.
J'ai procédé à un test simple, j'ai splité chaque ligne du tableau de relevé bancaire et je l'ai passé à Tesseract pour voir comment il réagissait. Le résultat est incroyable, désormais, tous les éléments sont restitués, il n'y a plus de partie manquante en sortie. Le seul petit bémol, c'est qu'il n'arrive toujours pas à gérer les alignements correctement.
En revanche l'IA peut gérer ce problème d'alignement :
Etant donné que chaque banque fourni systématiquement un format spécifique avec des alignements toujours identiques, on pourrait imaginer un système qui s'appuie sur de l'object detection en IA, qui serait dédié à chaque type de banque afin d'avoir une reconnaissance automatique des colonnes du relevés à savoir : date, libellé, débit, crédit.
L'object détection consiste à faire détecter des éléments à l'IA. Pour ce faire, on va marquer ces éléments sur plusieurs images et entrainer un modèle sur ces marquages jusqu'à ce qu'il sache de lui même les repérer lorsqu'on lui passe un flux (image, vidéo ou autre).
Pourquoi je veux absolument faire un modèle d'object detection dédié par banque ?
En machine learning, le nerf de la guerre c'est la data.
Il faut avoir énormément de données sources pour que le modèle puisse s'entrainer et assimiler. Le problème d'un modèle unique, multi banque, c'est que je vais devoir avoir une quantité énorme de documents à fournir et à marquer. Alors qu'un modèle dédié, me permettrait de fournir une vingtaine de fichier par banque, car on couvrirait une quantité raisonnable de cas et je pense que cela serait suffisant pour que l'IA comprenne quel élément correspond à quelle colonne.
Le plan d'attaque
Voici comment je vais procéder :
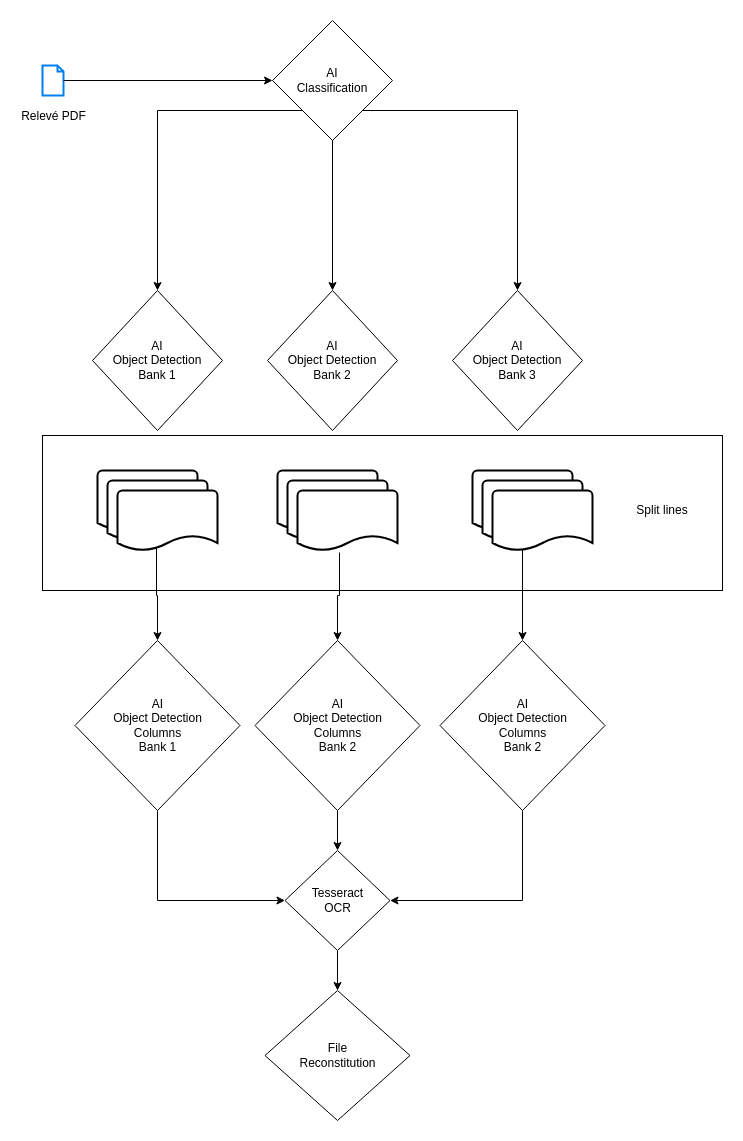
Je vais commencer par faire de la classification, puis, par banque, je vais faire de l'object detection pour extraire les lignes qui m'intéressent de manière splittée, ensuite je vais refaire de l'object detection sur chaque ligne afin de repérer les colonnes et enfin je vais assembler les données.
Qu'est-ce que la classification ?
Plus haut, je vous parlait de l'object detection. De la même manière, la Classification est une méthodologie en IA qui permet de déterminer visuellement quel type d'élément on manipule. C'est de cette façon que les développeur créent des classificateurs Chats/Chiens, etc...

Nous allons entraîner un modèle qui permet de déterminer quel est le nom de la banque du relevé que l'on fourni. De manière général, c'est un procédé très simple qui consiste à mettre dans un dossier plusieurs éléments d'une même famille afin de les regrouper. Une fois le modèle d'IA entraîné, il saura de lui même, à quelle famille appartient cet élément.
Pour la classification je me sers de Tensorflow. Je vais créer un réseau neuronal assez classique, en 9 couches.
L'object detection
Ensuite, une fois que nous savons quelle est la banque concernée par le relevé, nous passons le relevé dans une autre moulinette qui va chercher à faire de l'object detection. Pour faire cela, nous allons utiliser un outil en Python qui s'appelle LabelImg. En gros, ça consiste à délimiter des zones et décrire ce qui s'y trouve.
Au passage, lorsque vous installez LabelImg, vous constaterez peut-être quelques bugs, mais pas de panique, c'est du Python, il suffit d'ouvrir les fichiers et de faire des fixs à la main (simple conversion float > int).
L'outil ressemble à ça :
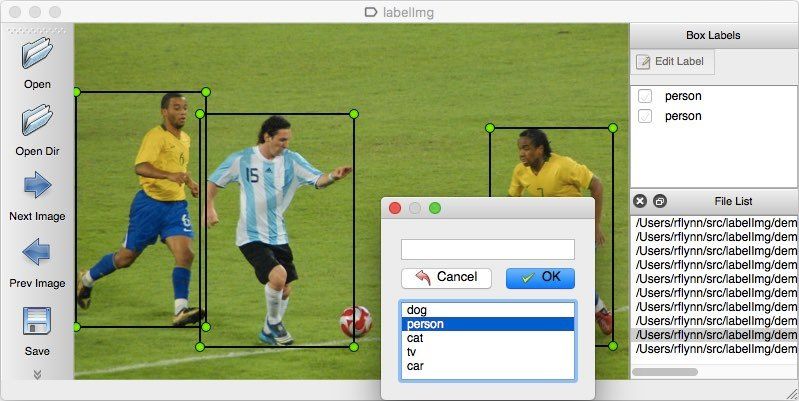
Je vais répéter ce procédé une dizaine de fois pour marquer chacun des relevés sur les éléments suivants: Logo, Information, Ligne.
Une fois ces 3 éléments annotés, le logo pourra nous confirmer de quelle banque il s'agit, les informations pourront être passé à l'OCR si besoin, et les lignes seront aussi converties par OCR pour générer un fichier de sortie.
Pour faire la détection, j'ai utilisé la librairie Yolo que j'ai entrainé sur un modèle custom à partir de mes relevés marqués par LabelImg. Après une série de tests je réalise que le modèle fonctionne bien mieux lorsque je paramètre un nombre très grand d'épochs (cycle d'entrainement du modèle).
Généralement, les épochs sont paramétrés à 100 sur des entraînements assez simple: détection d'humain, détection de voiture.
Dans notre cas, nous essayons de détecter un élément écrit parmi tant d'autres et il va falloir comprendre en quoi ils sont différents. J'ai effectué des tests pendant une journée entière sur un petit nombre d'épochs et, il m'était impossible d'avoir une bonne qualité de détection en sortie. D'autant plus que les images sont redimmensionnés pendant le passage au réseaux neuronal, ce qui fera la vitesse et l'efficacité de la détection dépend énormément de la compression de l'image. Si elle est trop grande, cela demandera beaucoup trop d'effort au matériel.
Tiens, tiens ! Le matériel... parlons en !
Pour entraîner un modèle comme celui-ci avec comme base Yolov8n (n pour nano: c'est un petit modèle pré-trained qui est déjà capable de détecter des objets de la vie quotidienne comme un téléphone, un ordinateur ou autre), mon ordinateur qui possède un GPU de type RTX 3060 Ti prends 20 minutes pour passer les 2000 epochs. Et la charge ram monte à 4go sur les 8go de disponible, il ne faut donc, pas lésiner sur les moyens:
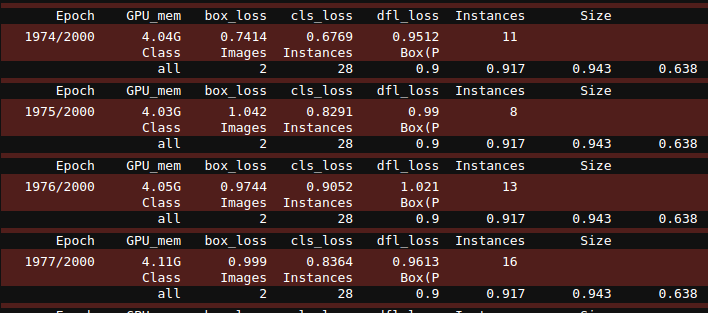
Il reste tout de même un avantage là dedans : le modèle est immédiatement sauvegardé. Je n'aurais donc pas à repasser par cette étape si je veux le réutiliser pour lancer immédiatement la détection.
J'ai lancé la détection sur un relevé Bred et voici le résultat :

Observez les petits décalages à gauches sur les lignes, ce n'est pas 100% parfait, mais ceci est dû au fait que je n'ai entraîné le modèle que sur une quantité réduite de documents (2 ou 3 pages, car c'est usant de faire du LabelImg). Je pense qu'avec plus de données, et plus d'épochs, je peux arriver à un résultat quasi parfait.
Compréhension des lignes
Après détection, on peut directement demander à extraire les matches au format texte. Mais pas si vite, on ne peut pas passer le résultat directement à l'OCR. J'ai fait le test avec un second relevé, de chez N26 :

Et là, nous rencontrons un problème :

Vous le voyez vous aussi ? Tesseract n'arrive pas à détecter les colonnes. Dans notre cas, il s'agit d'un débit, mais comme il n'arrive pas à gérer les offsets, il faut repasser par une étape de détection, cette fois ci, beaucoup plus simple. Qui consiste à dire, pour telle banque, voici la position des colonnes.
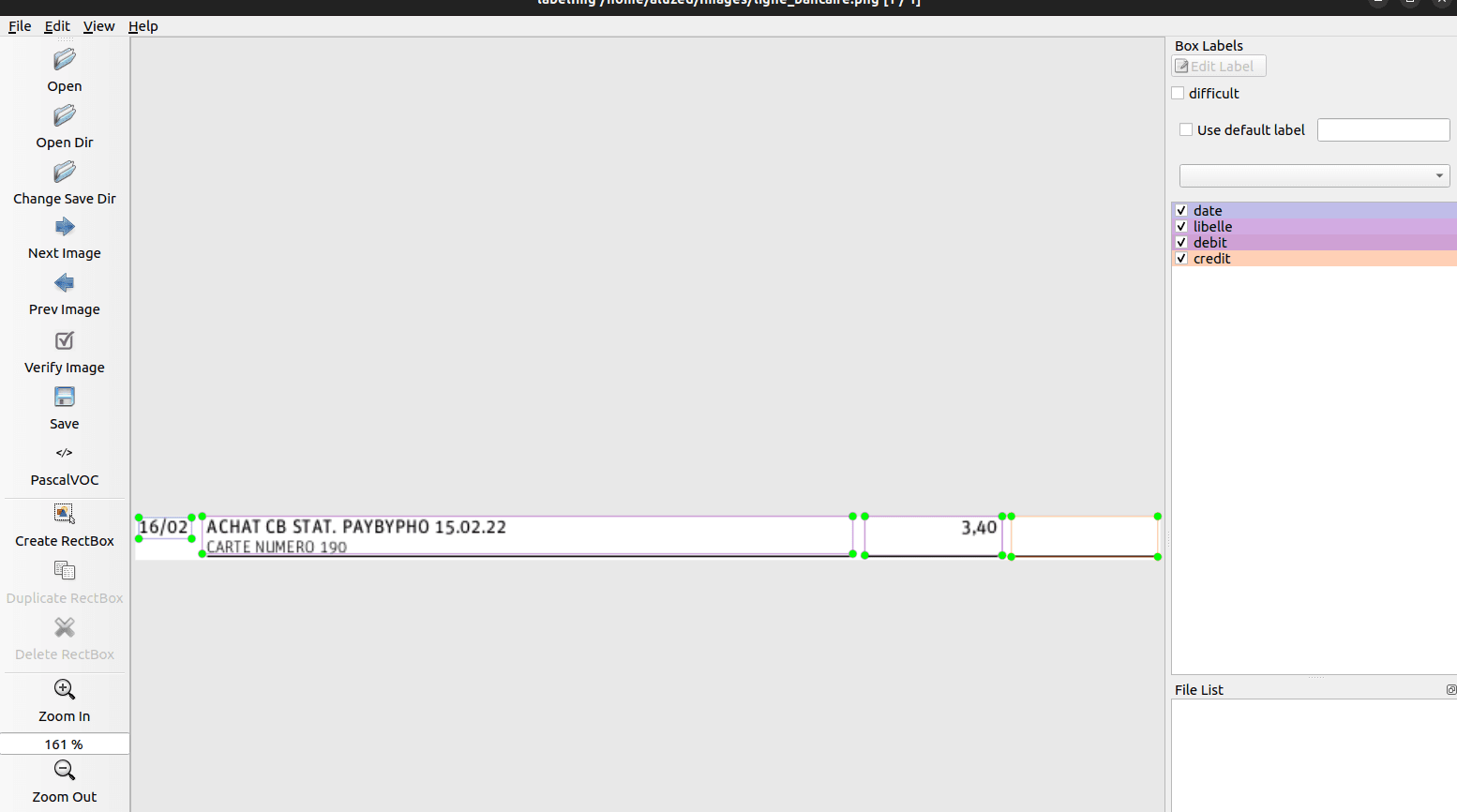
Nous pourrons ainsi, de la même façon que l'object detection de lignes, obtenir le champs dédié et faire un simple OCR sur ce champs.
On récupère chacune des lignes dans un tableau de dict et le tour est joué, on peut en faire un txt, un csv, ou autre.
Bilan
C'était un petit projet passionnant, j'ai adoré la phase exploratoire ou je me demandais toujours : Comment je vais procéder ? Quel outil je vais pouvoir utiliser ?
Après avoir identifié ce dont j'aurai besoin, le départ a été plutôt fastidieux car la mise en place des réseaux de neurones, la partie tweaking du réseau pour que ça fonctionne comme attendu, a été assez longue. J'ai dû y passer 2 à 3 jours. Mais au final, j'ai réussi avec aussi peu de données en entrée (entrainement) à faire un petit extracteur de mouvements pour les relevés bancaires. Je pense que si j'y passe 1 mois, j'obtiendrai quelque chose de très puissant (exploitable sous forme de SaaS j'entends).
Python est un langage simple et accessible, et les outils de machine learning sont légions sur ce langage. Internet regorge d'exemples et de tutos que vous pourrez suivre pour vous aussi vous y mettre. Une fois que l'on a compris quelques principes, ce n'est pas très compliqué. Si c'est un sujet qui vous intéresse depuis longtemps, mais que vous n'avez toujours pas franchi le pas, vous devriez vous y mettre.
FAQ
Pourquoi ne pas simplement passer le PDF scanné directement à Tesseract ?
Tesseract gère mal les mises en page complexes comme les tableaux bancaires : il peut mélanger des colonnes éloignées ou ignorer des portions entières du document. Il faut d'abord découper le document en zones ciblées avant de lui confier la reconnaissance de caractères.
Combien de documents faut-il pour entraîner un modèle par banque ?
Une vingtaine de relevés annotés par banque semble suffisant pour obtenir des résultats corrects, à condition d'utiliser un nombre d'epochs élevé lors de l'entraînement. Un modèle unique multi-banque nécessiterait une quantité de données bien plus importante.
Quel matériel est nécessaire pour entraîner ce type de modèle ?
Une carte graphique dédiée est fortement recommandée. Avec une RTX 3060 Ti, l'entraînement sur 2000 epochs prend environ 20 minutes et consomme jusqu'à 4 Go de RAM GPU. Sans GPU performant, les temps d'entraînement deviendraient très pénalisants.
C'est quoi concrètement la différence entre classification et object detection ici ?
La classification sert à identifier quelle banque a émis le relevé, en reconnaissant visuellement le document dans son ensemble. L'object detection, elle, localise précisément des zones dans l'image, comme les lignes ou le logo, pour les traiter séparément.
Combien de temps faut-il pour monter un tel projet ?
L'auteur estime avoir passé deux à trois jours sur la mise en place et le réglage des réseaux de neurones. Il pense qu'un mois de travail supplémentaire suffirait à obtenir quelque chose d'assez robuste pour une exploitation commerciale.

Alexandre P.
Développeur passionné depuis plus de 20 ans, j'ai une appétence particulière pour les défis techniques et changer de technologie ne me fait pas froid aux yeux.
Poursuivre la lecture

